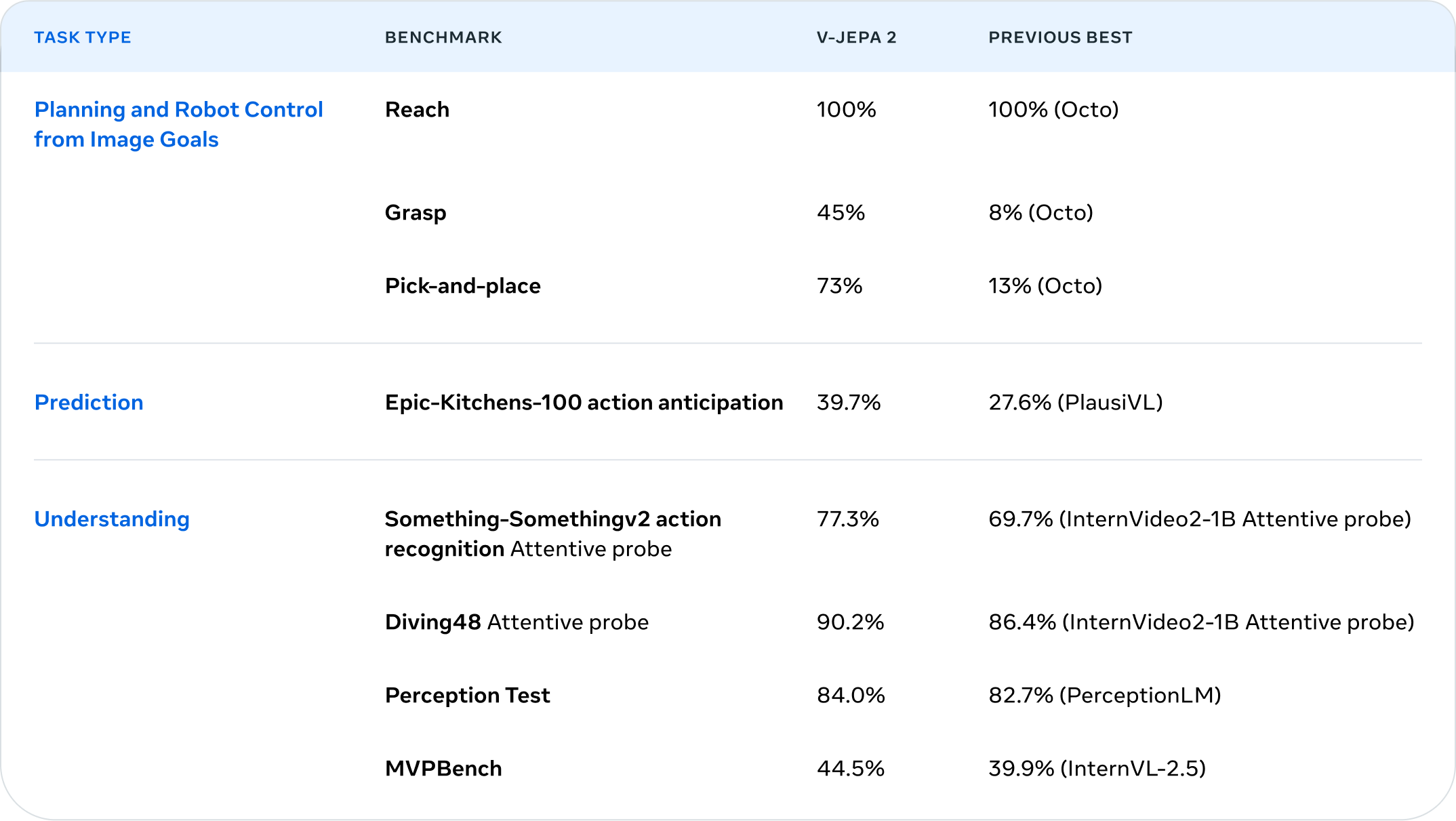
Meta's AI research team has introduced V-JEPA 2, a next-generation video model trained on over 1 million hours of internet video and 1 million images. This self-supervised model enables robots to understand the physical world, make predictions, and plan actions—without relying on labeled data or task-specific rewards.
Excelling in motion understanding, human action anticipation, object recognition, and video question answering, V-JEPA 2 sets new benchmarks in the field. Meta has also developed V-JEPA 2-AC, a variant that, after being fine-tuned on just 62 hours of robot interaction data, can perform real-world tasks like grasping and placing objects—zero-shot, in new environments, and without additional training.
These innovations represent a significant step toward more general-purpose, adaptable robots. With future alignment to language models, Meta aims to allow natural goal-setting for robots using simple voice or text instructions.