A new compression algorithm promising to radically shrink the working memory of AI models has sent shockwaves through the technology industry. Developed by Google Research, TurboQuant reduces the Key-Value (KV) cache memory used during large language model inference by at least 6x while maintaining zero accuracy loss. The algorithm requires no training or fine-tuning and introduces negligible runtime overhead. The research was led by Amir Zandieh, Research Scientist at Google, and Vahab Mirrokni, VP and Google Fellow.
TurboQuant operates through a two-stage compression framework built on two underlying algorithms: PolarQuant and QJL (Quantized Johnson-Lindenstrauss). In the first stage, PolarQuant converts data vectors from Cartesian to polar coordinates, completely eliminating the expensive normalization step and quantization constant overhead that conventional methods require. In the second stage, QJL uses just 1 bit of residual compression budget to correct the small error remaining from the first stage, removing systematic bias. Together, these stages deliver compression quality approaching information-theoretic lower bounds.
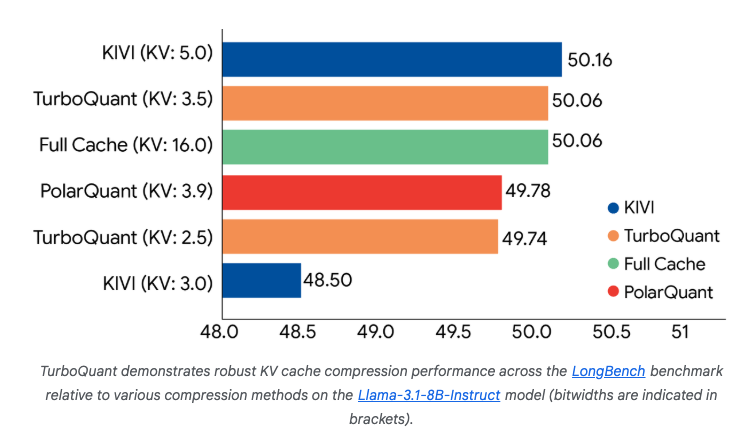
The experimental results are remarkably strong. Tested across five standard benchmarks — LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval — using open-source models Gemma and Mistral, TurboQuant matched or outperformed existing methods on every task. On NVIDIA H100 GPUs, 4-bit TurboQuant achieved up to an 8x speedup in computing attention logits compared to 32-bit unquantized keys. In vector search evaluation on the GloVe dataset, it achieved the highest recall ratios against competitors that rely on large codebooks and dataset-specific tuning.
The announcement triggered rapid movement across the tech ecosystem. Within 24 hours, community members began porting the algorithm to popular local AI libraries such as MLX for Apple Silicon and llama.cpp. Meanwhile, analysts observed a downward trend in stock prices of major memory suppliers including Micron and Western Digital. Set to be presented at ICLR 2026 next month, TurboQuant stands as a powerful signal that the next era of AI progress will be defined by mathematical elegance rather than brute-force scaling.