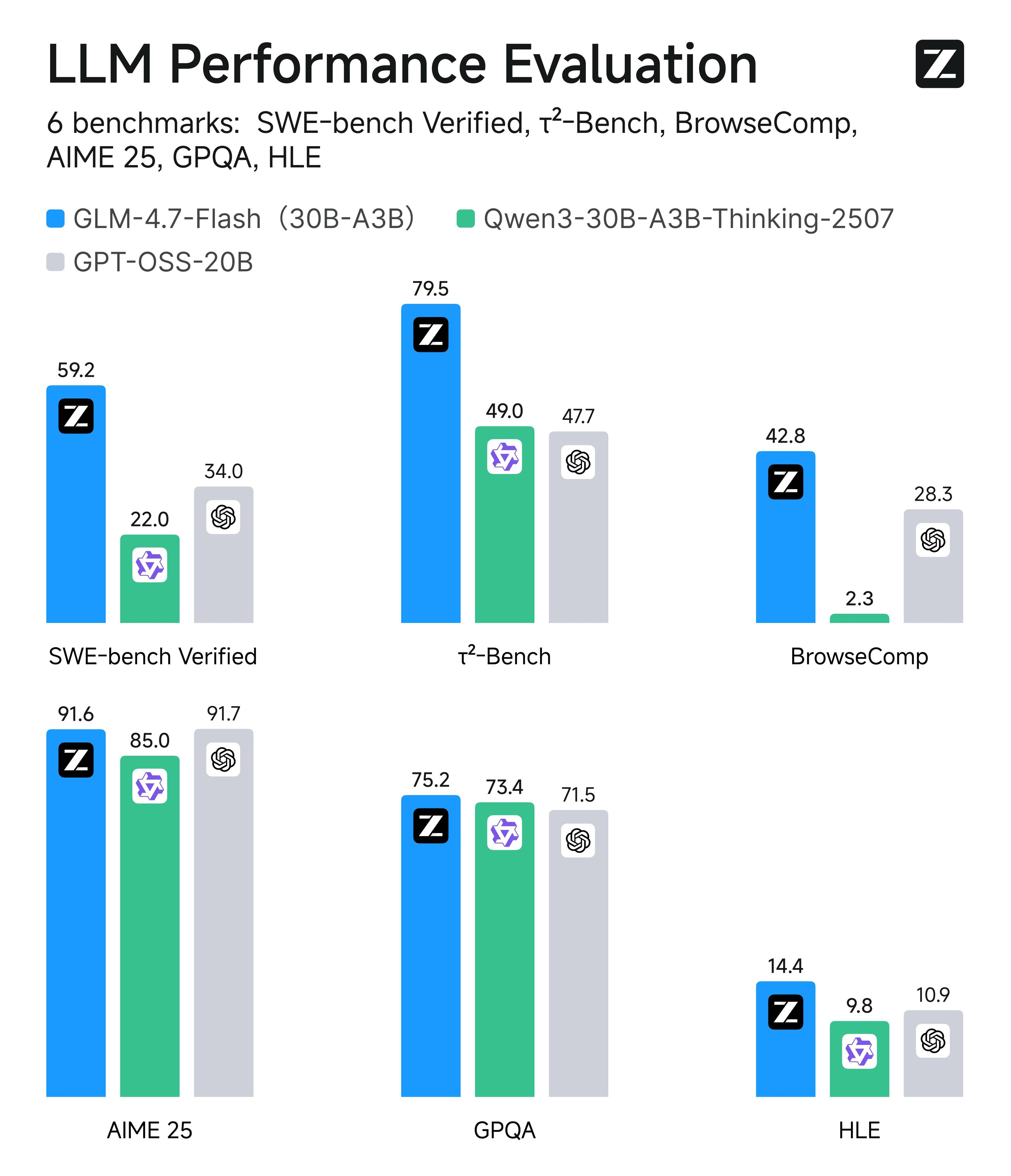
Z.ai has officially launched GLM-4.7-Flash, marking a significant milestone for the open-source AI ecosystem. Positioned in the 30B parameter class, the model leverages a Mixture-of-Experts (MoE) architecture, activating only 3B parameters per token to deliver high-speed inference with improved efficiency.
One of the most notable aspects of GLM-4.7-Flash is its free API access with no credit card requirement. Unlike typical “demo-tier” models, GLM-4.7-Flash is already being integrated into real-world developer tools such as Claude Code, Cline, Roo Code, and OpenCode, signaling strong early adoption.
The model is optimized for coding tasks, tool invocation, and agent-based workflows. Benchmark tests and local deployments across multiple quantization levels demonstrate that GLM-4.7-Flash maintains impressive token throughput while operating within relatively low memory constraints, especially in Q5 and Q6 configurations.
While it does not fully match the advanced reasoning capabilities of its larger GLM-4.7 counterparts with enabled Thinking modes, GLM-4.7-Flash stands out as a fast, accessible, and practical solution for prototyping, frontend generation, and interactive application development. Industry observers suggest it could become a cornerstone model for local AI deployments and cost-efficient developer workflows.