Chinese AI lab DeepSeek released its fourth-generation large language model family, branded "V4 Preview," on April 24, 2026. The launch includes two open-weight Mixture-of-Experts models: DeepSeek-V4-Pro with 1.6 trillion total parameters, and DeepSeek-V4-Flash with 284 billion. Both models support a 1-million-token context window, ship under the MIT license, and are available on Hugging Face, through the company's API, and via chat.deepseek.com, where they map to Expert Mode and Instant Mode respectively.
V4-Pro activates 49 billion parameters per token, while Flash activates 13 billion. Both were pre-trained on more than 32 trillion tokens. Architectural changes include a hybrid attention layer that combines Compressed Sparse Attention with Heavily Compressed Attention, Manifold-Constrained Hyper-Connections (mHC), and the Muon optimizer. According to DeepSeek's technical report, at a 1-million-token context length V4-Pro uses only 27 percent of the per-token inference FLOPs and 10 percent of the KV cache required by V3.2. V4-Flash reduces those figures further, to 10 percent and 7 percent respectively.
DeepSeek first drew global attention in January 2025 with its low-cost R1 reasoning model, which briefly rattled U.S. equity markets and contributed to a sharp drop in NVIDIA stock. The V4 release was originally rumored for February 2026 but was pushed back multiple times, partly because sections of the model stack were rewritten for compatibility with Huawei's Ascend chips, according to reporting by Reuters and The Information. With 1.6 trillion total parameters, V4-Pro is now the largest open-weight model publicly available, surpassing Kimi K2.6 at 1.1 trillion and GLM-5.1 at 754 billion.
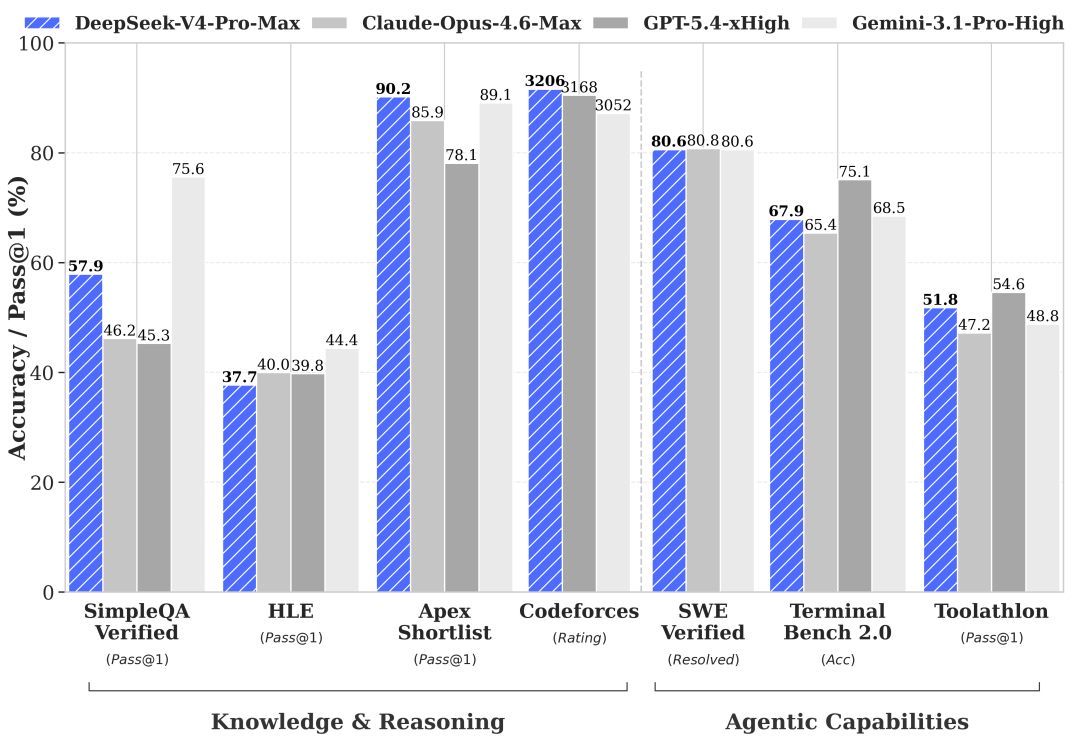
On benchmarks published alongside the release, V4-Pro tops LiveCodeBench at 93.5 and posts a Codeforces rating of 3,206, ahead of GPT-5.4's 3,168. DeepSeek acknowledges, however, that closed-source frontier models including Gemini 3.1 Pro and Claude Opus 4.6 retain the lead on general knowledge, long-context retrieval, and several agentic-coding benchmarks. V4-Pro is priced at $1.74 per million input tokens and $3.48 per million output tokens — roughly a seventh of Claude Opus 4.7's output rate. The existing "deepseek-chat" and "deepseek-reasoner" endpoints, currently routed to V4-Flash, will be retired after July 24, 2026.