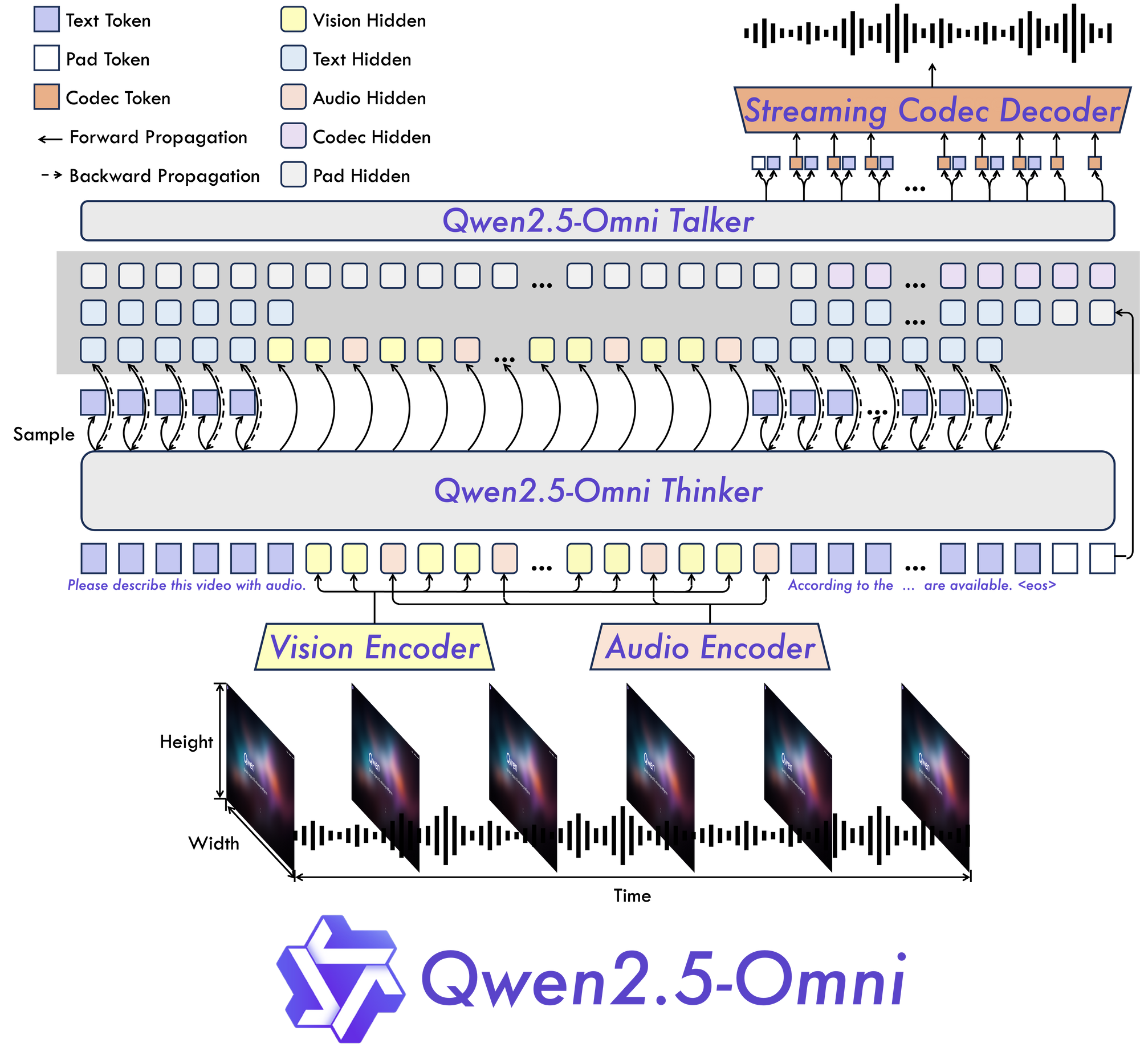
Alibaba Cloud has unveiled its latest milestone in artificial intelligence with the introduction of the Qwen2.5-Omni-7B model. This innovative model is equipped with extensive multimodal perception capabilities, enabling it to process diverse inputs including text, images, audio, and video. The Qwen 2.5 Omni model can generate real-time responses, facilitating more human-like interactions through natural dialogue.
At the core of this model lies its unique "Thinker-Talker" architecture, which separates cognitive processing (thinking) from output generation (talking). This design efficiently manages the complexities inherent in multimodal data. Additionally, its Time-aligned Multimodal RoPE (TMRoPE) mechanism addresses the challenges of synchronizing temporal data. For instance, it can align visual events with corresponding audio or speech, significantly enhancing its ability to process simultaneous video and audio streams.
Designed for real-time interactions, Qwen2.5-Omni-7B supports low-latency streaming, making it especially suited for applications like voice assistants and live video analysis. The model holds great promise across various functionalities like immersive customer service solutions, comprehensive content analysis, and creative educational materials that can respond to student inquiries in real-time.
In conclusion, Alibaba Cloud's Qwen2.5-Omni-7B stands out as a remarkable advancement in the realm of multimodal AI, poised to revolutionize interactions in diverse fields ranging from healthcare to education. This model promises to make AI interactions more natural and intuitive, breaking down barriers between different communication forms.